Flutter is an open source UI framework, released in 2017 by Google, that allows the creation of multi-platform applications, without having to worry about constraints related to supported platforms.
Flutter applications are written in a programming language called Dart, then compiled and run as a native applications, to be efficiently executed on Linux, Android, iOS or Windows platforms, but also as Web applications.
On Linux platforms, Flutter can be used on top of several graphic back-ends:
DRM
Wayland
X11
Flutter is composed of four main parts:
the embedder (C++, Java…): the glue for specific platforms that provides surface rendering, vsync.
the engine (C/C++): the graphic engine based on Skia, that provides asset resolution, graphics shell, Dart VM…
the framework (Dart): to create UI by using widgets, animation…
the applications (Dart)
In this article, we show how to build a custom Linux distribution that includes a Flutter Embedder that uses the DRM/EGLStream backend, in order to run the Flutter Gallery application on the NVIDIA Tegra Xavier NX platform.
In addition, we will also extend a Yocto SDK to embed the Flutter toolchain, to be able to build Flutter applications directly with the SDK.
Configure Yocto and build an image
To build our Flutter-enabled Linux distribution, we have chosen to use OpenEmbedded, driven through the Kas utility. Kas is a tool developed by Siemens to facilitate the setup of projects based on Bitbake, such as OpenEmbedded or Yocto.
Kas relies on a YAML file that indicates the information required to:
clone bitbake and required layers
configure the build environment
launch bitbake process
Below is the Kas YAML file that we created for this example:
The meta-flutter layer, which contains all the Flutter related recipes
The meta-tegra layer, which is our BSP layer containing all the bootloader/kernel and machine-specific recipes for the Nvidia Jetson Xavier NX platform
The meta-clang layer, which is needed by the meta-flutter layer, as Flutter is built using the Clang compiler
As we chose to use a DRM/EGLStream backend of Flutter we extend the DISTRO_FEATURES to enable the support of OpenGL and Wayland:
DISTRO_FEATURES:append = " opengl wayland"
In addition, we extend the list of packages that will be installed in the image with the ones that provide the Flutter embedder and the Gallery application:
Finally, we also install the package that provides a configuration to set the correct modeset when the Tegra direct rendering module is probed.
IMAGE_INSTALL:append = " tegra-udrm-probeconf"
Using this YAML file, we can instruct Kas to launch the build:
kas build kas-flutter-example.yml
Storage flash process
Images and Nvidia tools to flash Jetson platforms are packaged into a tarball built and deployed as a target image into the folder build/tmp-glibc/deploy/images.
The SD card image for the Jetson Xavier NX can be flashed in two different ways:
from the target board,
from the host.
Here, we explain how to flash it from the target board.
Note: Each Jetson model has its own particular storage layout.
First, we need to extract the tegraflash archive:
mkdir tegraflash
cd tegraflash
tar -xvzf ../build/tmp-glibc/deploy/images/jetson-xavier-nx-devkit/core-image-minimal-jetson-xavier-nx-devkit.tegraflash.tar.gz
Moreover, to be able to flash the Jetson Xavier NX, it is required to switch it in recovery mode. For that it is necessary to connect a jumper between the 3rd and 4th pins from the right hand side of the “button header” underneath the back of the module (FRC and GND; see the labeling on the underside of the carrier board).
With this done, the module will power up in recovery mode automatically and will be visible from the host PC as an additional USB device:
lsusb |egrep 0955
Bus 003 Device 047: ID 0955:7e19 NVIDIA Corp.
Overall, here are the steps to follow to flash the SD card and the SPI Nand:
Start with your Jetson powered off.
Enable the recovery mode, as indicated above.
Connect the USB cable from your Jetson to your development host.
Insert an SD card into the slot on the module.
Power on the Jetson and put it into recovery mode.
Execute ./doflash.sh from the extracted tegraflash archive.
Finally, the target will boot.
Launch the Flutter application
Now, it is possible to start the Flutter Gallery application which is part of the core-image-minimal image, together with the Flutter stack, with the following command:
The OpenEmbedded build system can also be used to generate an application development SDK, that is a self-extracting tarball containing a cross-development toolchain, libraries and headers. This allows application developers to build, deploy and debug applications without having to do the OpenEmbedded build themselves.
It is possible to enrich the SDK’s sysroots with additional packages, through the variables TOOLCHAIN_HOST_TASK and TOOLCHAIN_TARGET_TASK.
That allows for example to extend the SDK with for example profiling tools, debug tools, symbols to be able to debug offline.
So, we used these variables to append the Flutter SDK and required dependencies to the Yocto SDK, to be able to cross-build Flutter applications with it.
To use the SDK, it is required to source the environment setup script that will set some cross-compile variables, like CC, LD, GDB, in the shell environment to develop or debug applications with SDK’s sysroots:
To illustrate how to use the SDK, let’s see how to build the Gallery Flutter application with the Yocto SDK. Before calling the flutter command, the SDK environment-setup script has been sourced and the following environment variables have been set:
FLUTTER_SDK: the path to the Flutter SDK into the Yocto SDK,
ENGINE_SDK: where the Flutter engine shall be built,
PATH: to extend the shell environment with Flutter tools provided by the SDK.
We can then retrieve the application source code:
git clone git@github.com:flutter/gallery.git
cd gallery
git checkout 9eb785cb997ff56c46e933c1c591f0a6f31454f6
Here, it is a workaround, that allows the flutter command line to correctly find the version of Flutter SDK:
Without the workaround above, the following error is raised:
The current Flutter SDK version is 0.0.0-unknown.
[...]
Failed to find the latest git commit date: VersionCheckError: Command exited with code 128: git -c log.showSignature=false log -n 1 --pretty=format:%ad --date=iso
Standard out:
Standard error: error: object directory build/downloads/git2/github.com.flutter.flutter.git/objects does not exist; check .git/objects/info/alternates
fatal: bad object HEAD
Returning 1970-01-01 01:00:00.000 instead.
[...]
Set the required environment variables and build the application for Linux:
export FLUTTER_SDK="${destination}/sysroots/x86_64-oesdk-linux/usr/share/flutter/sdk"
export PATH=${FLUTTER_SDK}/bin:$PATH
export ENGINE_SDK="./engine_sdk/sdk"
flutter config --enable-linux-desktop
flutter doctor -v
flutter build linux --release
flutter build bundle
This gives you the Flutter application, ready to run on the target!
Conclusion
In this blog post, we have shown that deploying Flutter on an OpenEmbedded distribution was a relatively easy process, and that the SDK can be extended to allow building Flutter applications.
This blog post is the first part of a series of 3 articles related to the PipeWire project and its usage in embedded Linux systems.
Introduction
PipeWire is a graph-based processing engine, that focuses on handling multimedia data (audio, video and MIDI mainly).
It has gained steam early on by allowing screen sharing on Wayland desktops, which for security reasons, does not allow an application to access any framebuffer that does not concern it. The PipeWire daemon was run with sufficient privileges to access screen data; giving access through a D-Bus service to requesting applications, with file-descriptor passing for the actual video transfer. It was as such bundled in the Fedora distribution, version 27.
Later on, the idea was to expand this to also allow handling audio streams in the processing graph. Big progress has been done by Wim Taymans on this front, and PipeWire is now the default sound server of the desktop Fedora distribution, since version 34.
The project is currently in active development. It happens in the open, lead by Wim Taymans. The API and ABI can both be considered stable, even though version 1.0 has not been released yet. The changelog exposes very few breaking changes (two years without one) and many bug fixes. It is developed in C, using a Meson and Ninja based build system. It has very few unconditional runtime dependencies, but we’ll go through those during our first install.
Throughout this series of blog articles, our goal will be to discover PipeWire and the possiblities it provides, focusing upon audio usage on embedded platforms. A detailed theoretical overview at the start will allow us to follow up with a hands-on approach. Starting with a minimal Buildroot setup on a Microchip SAMA5D3 Xplained board, we will create then our own custom PipeWire source node. We will then study how dynamic, low-latency routing can be done. We’ll end with experiments regarding audio-over-ethernet.
A note: we will start with many theoretical aspects, that are useful to get a good mental model of the way PipeWire works and how it can be used to implement any wanted behavior. This introduction might therefore get a little exhaustive at times, and it could be a good approach to skip even if a concept isn’t fully grasped, to come back later during hands-ons when details on a specific subject is required.
Sky-high overview
A PipeWire graph is composed of nodes. Each node takes an arbitrary number of inputs called ports, does some processing over this multimedia data, and sends data out of its output ports. The edges in the graph are here called links. They are capable of connecting an output port to an input port.
Nodes can have an arbitrary number of ports. A node with only output ports is often called a source, and a sink is a node that only possesses input ports. For example, a stereo ALSA PCM playback device can be seen as a sink with two input ports: front-left and front-right.
Here is a visual representation of a PipeWire graph instance, provided by the Helvum GTK patchbay:
Screenshot provided by the Helvum project
Visual attributes are used in Helvum to describe the state of nodes, ports and links:
Node names are in white, with their ports being underneath the names. Input ports are on the left while output ports are on the right.
“Dummy-Driver” and “Freewheel-Driver” nodes have no ports. Those two are particular sinks (with dynamic input ports, that appear when we connect a node to them) used in specific conditions by PipeWire.
Red means MIDI, yellow means video and blue means audio.
Links are solid when active (data is “passing-through” them) and dashed when in a paused state.
Note: if your Linux desktop is running PipeWire, trying installing Helvum to graphically monitor and edit your multimedia graph! It is currently packaged on Fedora, Arch Linux, Flathub, crates.io and others.
Design choices
There are a few noticeable design choices that explain why PipeWire is being adopted for desktop and embedded Linux use cases.
Session and policy management
One first design choice was to avoid tackling any management logic directly inside PipeWire; context-dependent behaviour such as monitoring for new ALSA devices, and configuring them so that they appear as nodes, or automatically connecting nodes using links is not handled. It rather provides an API that allows spawning and controlling those graph objects. This API is then relied upon by client processes to control the graph structure, without having to worry about the graph execution process.
A pattern that is often used and is recommended is to have a single client be a daemon that deals with the whole session and policy management. Two implementations are known as of today:
pipewire-media-session, which was the first implementation of a session manager. It is now called an example and used mainly in debugging scenarios.
WirePlumber, which takes a modular approach: it provides another, higher-level API compared to the PipeWire one, and runs Lua scripts that implement the management logic using the said API. In particular, this session manager gets used in Fedora since version 35. It ships with default scripts and configuration that handle linking policies as well as monitoring and automatic spawning of ALSA, bluez, libcamera and v4l2 devices. The API is available from any process, not only from WirePlumber’s Lua scripts.
Individual node execution
As described above, the PipeWire daemon is responsible for handling the proper processing of the graph (executing nodes in the right order at the right time and forwarding data as described by links) and exposing an API to allow authorized clients to control the graph. Another key point of PipeWire’s design is that the node processing can be done in any Linux process. This has a few implications:
The PipeWire daemon is capable of doing some node processing. This can be useful to expose a statically-configured ALSA device to the graph for example.
Any authorized process can create a PipeWire node and be responsible for the processing involved (getting some data from input ports and generating data for output ports). A process that wants to play stereo audio from a file could create a node with two output ports.
A process can create multiple PipeWire nodes. That allows one to create more complex applications; a browser would for example be able to create a node per tab that requests the ability to play audio, letting the session manager handle the routing: this allows the user to route different tab sources to different sinks. Another example would be an application that requires many inputs.
API and backward compatibility
As we will see later on, PipeWire introduces a new API that allows one to read and write to the graph’s overall state. In particular, it allows one to implement a source and/or sink node that will be handling audio samples (or other multimedia data).
One key point for PipeWire’s quick adoption is a focus on providing a shim layer to currently-widespread audio API in the Linux environment. That is:
It can obviously expose ALSA sinks or sources inside the graph. This is at the heart of what makes PipeWire useful: it can interact with local audio hardware. It uses alsa-lib as any other ALSA client. PipeWire is also capable of creating virtual ALSA sinks or sources, to interface with applications that rely solely upon the alsa-lib API.
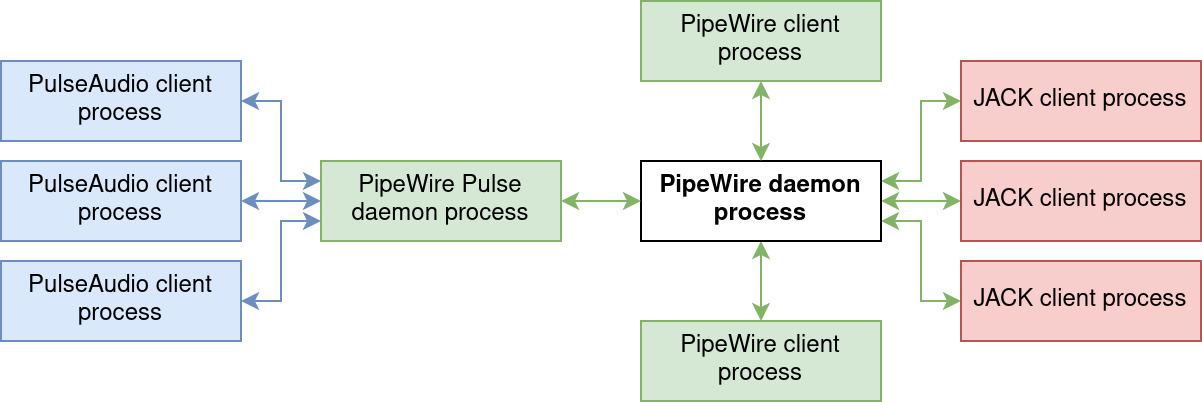
It can implement the PulseAudio API in place of PulseAudio itself. This simply requires starting a second PipeWire daemon, with a specific pulse configuration. Each PulseAudio sink/source will appear in the graph, as if native. PulseAudio is the main API used by Linux desktop users and this feature allows PipeWire to be used as a daily-driver while supporting all standard applications. An anecdote: relying on the PulseAudio API is still recommended for simple audio applications, for its more widespread and simpler API.
It also implements the JACK Audio Connection Kit (or JACK); this API has been in use by the pro-audio audience and targets low-latency for audio and MIDI connections between applications. This requires calling JACK-based applications using pw-jack COMMAND, which does the following according to its manual page:
pw-jack modifies the LD_LIBRARY_PATH environment variable so that applications will load PipeWire’s reimplementation of the JACK client libraries instead of JACK’s own libraries. This results in JACK clients being redirected to PipeWire.
Schema illustrating the way PulseAudio and JACK applications are supported
About compatibility with Linux audio standards, the PipeWire FAQ has an interesting answer to the expected question whenever something new appears: why another audio standard, Linux already has 13 of them? For exhaustiveness, here is a quick rundown of the answer: it describes how Linux has one kernel audio subsystem (ALSA) and only two userspace audio servers: PulseAudio and JACK. Others are either frameworks relying on various audio backends, dead projects or wrappers around audio backends. PipeWire’s goal, on the audio side, is to provide an alternative to both PulseAudio and JACK.
Real-time execution: push or pull?
In the simple case of a producer and a consumer of data, two execution models are in theory possible:
Push, where the producer generates data when it can into a shared buffer, from which the consumer reads. This is often associated with blocking writes to signal the producer when the buffer is full.
Pull, where the producer gets signaled when data is needed for the consumer, at which point the producer should generate data as fast as possible into the given shared buffer.
In a real-time case scenario, latency is optimal when the data quantity in the shared buffer is minimised: when the producer adds data to the buffer, all the data already present in the buffer needs to be consumed before the new data gets processed as well. As such, the pull method allows the system to monitor the shared buffer state and signal the producer before the shared buffer gets empty; this guarantees data that is as up-to-date as possible as it was generated as late as possible.
That was for a generic overview of pushed versus pulled communication models. PipeWire adopts the pull model as it has low latencies as a goal. Some notes:
The structure is more complex compared to a single producer and single consumer architecture, as there can be many more producers and consumers, possibly with nodes depending on multiple other nodes.
The PipeWire daemon handles the signaling of nodes. Those get woken up, fill a shared memory buffer and pass it onto its target nodes; those are the nodes that take its output as an input (as described by link objects).
The concept of driver nodes is introduced; other nodes are called followers. For each component (subgraph of the whole PipeWire graph), one node is the driver and is responsible for timing information. It is the one that signals PipeWire when a new execution cycle is required. For the simple case of an audio source node (the producer) and an ALSA sink node (the consumer), the ALSA sink will send data to the hardware according to a timer, signaling PipeWire to start a new cycle when it has no more data to send: it pulls data from the graph by telling it that it needs more.
Note: in this simple example, the buffer size provided to ALSA by PipeWire determines the time we have to generate new data. If we fail to execute the entire graph in time before the timer, the ALSA sink node will have no data and this will lead to an underrun.
Implementation overview
This introduction and the big design decisions naturally lead us to have a look at the actual implementation concepts. Here are the questions we will try to answer:
How is the graph state represented?
How can a client process get access to the graph state and make changes?
How is IPC communication handled?
Graph state representation: objects, objects everywhere
As said previously, PipeWire’s goal is to maintain, execute and expose a graph-structured multimedia execution engine. The graph state is maintained by the PipeWire daemon, which runs the core object. A fundamental principle is the concept of an object. Clients communicate with the core using IPC, and can create objects of various types, which can then be exported. Exporting an object means telling the core and its registry about it, so that the object becomes a part of the graph state.
Every object have at least the following: a unique integer identifier, some permissions flags for various operations, an object type, string key-value pairs of properties, methods and event types.
Object types
There is a fixed type list, so let’s go through the main existing types to understand the overall structure better:
The core is the heart of the PipeWire daemon. There can only be one core per graph instance and it has the identifier zero. It maintains the registry, which has the list of exported objects.
A client object is the representation of an open connection with a client process, from within the daemon process.
A module is a shared object that is used to add functionality to a PipeWire client. It has an initialisation function that gets called when the module gets loaded. Modules can be loaded in the core process or in any client process. Clients do not export to the registry the modules they load. We’ll see examples of modules and how to load them later on.
A node is a producer and/or consumer of data; its main characteristic is to have input and output port objects, which can be connected using link objects to create the graph structure.
A port belongs to a node and represents an input or output of data. As such, it has a direction, a data format and can have a channel position if it is audio data that is being transferred.
A link object connects two ports of opposite direction together; it describes a graph edge.
A device is a handle representing an underlying API, which is then used to create nodes or other devices. Examples of devices are ALSA PCM cards or V4L2 devices. A device has a profile, which allows one to configure them.
A factory is an object whose sole capability is to create other objects. Once a factory is created, it can only emit the type of object it declared. Those are most often delivered as a module: the module creates the factory and stays alive to keep it accessible for clients.
A session object is supposed to represent the session manager, and allow it to expose APIs through the PipeWire communication methods. It is not currently used by WirePlumber but this is planned.
An endpoint is the concept of a (possibly empty) grouping of nodes. Associated with endpoint streams and links, they can represent a higher-level graph that is handled by the session manager. Those would allow modeling complex behaviors such as mutually-exclusive sinks (think laptop speakers and line-out port) or nodes to which PipeWire cannot send audio streams, such as analog peripherals for which the streams do not go through the CPU. Those peripherals would therefore appear in the graph, be controlled with the same API (routing using links, setting volume, muting, etc.) but the processing would be done outside PipeWire’s reach. See PipeWire’s documentation for more information on the potential of those advanced features.
Permissions
The session and policy manager (most often WirePlumber) is also responsible for defining the list of permissions each client has. Each permission entry is an object ID and four flags. A special PW_ID_ANY ID means that those permissions are the default, to be used if a specific object is not described by any other permission. Here are the four flags:
Read: the object can be seen and events can be received;
Write: the object can be modified, usually through methods (which requires the execute flag);
eXecute: methods can be called;
Metadata: metadata can be set on the object.
This isn’t well leveraged upon yet, as all clients get default permissions of rwxm: read, write, execute, metadata.
Properties
All objects also have properties attributed to them, which is a list of string key-value pairs. Those are abitrary and various keys are expected for various object types. An example link object has the following properties (as reported by pw-cli info LINK_ID):
# Link ID
object.id = "95"
# Source port
link.output.node = "91"
link.output.port = "93"
# Destination port
link.input.node = "80"
link.input.port = "86"
# Client that created the link
client.id = "32"
# Factory that was called to create the link
factory.id = "20"
# Serial identifier: an incremental identifier that guarantees no
# duplicate across a single instance. That exists because standard
# IDs get reused to keep them user-friendly.
object.serial = "677"
Parameters
Some object types also have parameters (often abbreviated as params), which is a fixed-length list of parameters that the object possesses, specific to the object type. Currently, nodes, ports, devices, sessions, endpoints and endpoint streams have those. Those params have flags that define if they can be read and/or written, allowing things like constant parameters defined at the object creation.
Parameters are the key that allow WirePlumber to negotiate data formats and port configuration with nodes: hardware that supports multiple sample rates? channel count and positions? sample format? enable monitor ports? etc. Nodes expose enumerations of what they are capable of, and the session manager writes the format/configuration it chose.
Methods & events
An object’s implementation is defined by its list of methods. Each object type has a list of methods that it needs to implement. One note-worthy method is process, that can be found on nodes. It is the one that eats up data from input ports and provides data for each output port.
Every object implement at least the add_listener method, that allows any client to register event listeners. Events are used through the PipeWire API to expose information about an object that might change over time (the state of a node for example).
Exposing the graph to clients: libpipewire and its configuration
Once an object is created in a process, it can be exported to the core’s registry so that it becomes a part of the graph. Once exported, an object is exposed and can be accessed by other clients; this leads us into this new section: how clients can get access and interact with the graph.
The easiest way to interact with a PipeWire instance is to rely upon the libpipewire shared object library. It is a C library that allows one to connect to the core. The connection steps are as follows:
Initialise the library using pw_init, whose main goal is to setup logging.
Create an event-loop instance, of which PipeWire provides multiple implementations. The library will later plug into this event-loop to register event listeners when requested.
Create a PipeWire context instance using pw_context_new. The context will handle the communication process with PipeWire, adding what it needs to the event-loop. It will also find and parse a configuration file from the filesystem.
Connect the context to the core daemon using pw_context_connect. This does two things: it initialises the communication method and it returns a proxy to the core object.
Proxies
A proxy is an important concept. It gives the client a handle to interact with a PipeWire object which is located elsewhere but which has been registered in the core’s registry. This allows one to get information about this specific object, modify it and register event listeners.
Event listeners are therefore callbacks that clients can register on proxy objects using pw_*_add_listener, which takes a struct pw_*_events defining a list of function pointers; the star should be replaced by the object type. The libpipewire library will tell the remote object about this new listener, so that it notifies the client when a new event occurs.
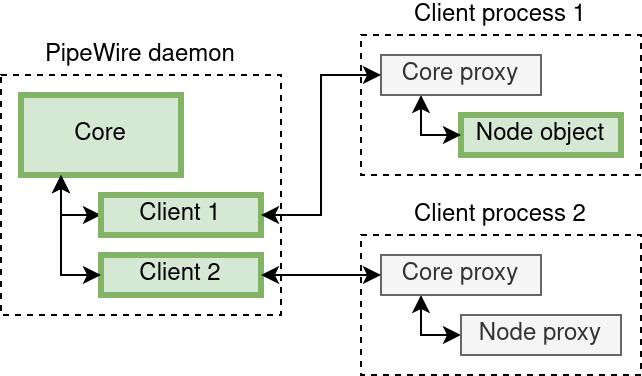
We’ll take an example to describe the concept of proxies:
Schema of a daemon and two clients, with one client having a proxy pointing to the remote node
In this schema, green blocks are objects (the core, clients and a node) and grey ones are proxies. Dotted blocks represent processes. Here is what would happen, in order, assuming client process 2 wants to get the the state of a node that lives in client process 1:
Client process 2 creates a connection with the core, that means:
On the daemon side, a client object is created and exported to the registry;
On the client side, a proxy to the core object is acquired, which represents the connection with the core.
It then uses the proxy to core and the pw_core_get_registry function to get a handle on the registry.
It registers an event listener on the registry’s global event, by passing a struct pw_registry_events to pw_registry_add_listener. That event listener will get called once for each object exported to the registry.
The global event handler will therefore get called once with the node as argument. When this happens, a proxy to the node can be obtained using pw_registry_bind and the info event can be listened upon using pw_node_add_listener on the node proxy with a struct pw_client_events containing the list of function pointers used as event handlers.
The info event handler will therefore be called once with a struct pw_node_info argument, that contains the node’s state. It will then be called each time the state changes.
The same thing is done in tutorial6.c to print every clients’ information.
Context configuration
When a PipeWire context is created using pw_context_new, we mentioned that it finds and parses a configuration file from the filesystem. To find a configuration file, PipeWire requires its name. It then searches for this file in following locations, $sysconfdir and $datadir being PipeWire build variables:
Firstly, it checks in $XDG_CONFIG_HOME/pipewire/ (most probably ~/.config/pipewire/);
Then, it looks in $sysconfdir/pipewire/ (most probably /etc/pipewire/);
As a last resort, it tries $datadir/pipewire/ (most probably /usr/share/pipewire/).
PipeWire ships with default configuration files, which are often put in the $datadir/pipewire/ path by distributions, meaning those get used as long as they have not been overriden by custom global configuration files (in $sysconfdir/pipewire/) or personal configuration files (in $XDG_CONFIG_HOME/pipewire/). Those are namely:
pipewire-pulse.conf, for the daemon process that implements the PulseAudio API;
client.conf, for processes that want to communicate using the PipeWire API;
client-rt.conf, for processes that want to implement node processing, RT meaning realtime;
jack.conf, used by the PipeWire implementation of the JACK shared object library;
minimal.conf, meant as an example for those that want to run PipeWire without a session manager (static configuration of an ALSA device, nodes and links).
The default configuration name used by a context is client.conf. This can be overriden either through the PIPEWIRE_CONFIG_NAME environment variable or through the PW_KEY_CONFIG_NAME property, given as an argument to pw_context_new. The search path can also be modified using the PIPEWIRE_CONFIG_PREFIX environment variable.
Make sure to go through one of them to get familiar with them! The format is described as a “relaxed JSON variant”, where strings do not need to be quoted, the key-value separator is an equal symbol, commas are unnecessary and comments are allowed starting with an hash mark. Here are the sections that can be found in a configuration file:
context.properties, that configures the context (log level, memory locking, D-Bus support, etc.). It is also used extensively by pipewire.conf (the daemon’s configuration) to configure the graph default and allowed settings.
context.spa-libs defines the shared object library that should be used when a SPA factory is asked for. The default values are best to be kept alone.
context.modules lists the PipeWire modules that should be loaded. Each entry has an associated comment that explains clearly what each modules does. As an example, the difference between client.conf and client-rt.conf is the loading of libpipewire-module-rt that turns on real-time priorities for the process and its threads.
context.objects allows one to statically create objects by providing a factory name associated with arguments. This is what is used by the daemon’s pipewire.conf to create the dummy node, or by minimal.conf to statically create an ALSA device and node as well as a static node.
context.exec lists programs that will be executed as childs of the process (using fork(2) followed by execvp(3)). This was primarily used to start the session manager; it is however recommended to handle its boot separately, using your init system of choice.
filter.properties and stream.properties are used in client.conf and client-rt.conf to configure node implementations. Filters and streams are the two abstractions that can be used to implement custom nodes, which we will talk in detail in a later article.
Inter-Process Communication (IPC)
Being a project that handles multimedia data, transfers it in-between processes and aims for low-latency, the inter-process communication it uses is at the heart of its implementation.
Event loop
The event-loop described previously is the scheduling mechanism for every PipeWire process (the daemon and every PipeWire client process, including WirePlumber, pipewire-pulse and others). This loop is an abstraction layer over the epoll(7) facility. The concept is rather simple: it allows one to monitor multiple file descriptors with a single blocking call, that will return once one file descriptor is available for an operation.
The main entry point to this event loop is pw_loop_add_source or its wrapper pw_loop_add_io, which adds a new file descriptor to be listened for and a callback to take action once an operation is possible. In addition to the loop instance, the file descriptor and the callback, it takes the following arguments:
A mask describing the operations for which we should be waken up: read(2) is possible (SPA_IO_IN), write(2) is possible (SPA_IO_OUT), an error occured (SPA_IO_ERR) and a hang-up occured (SPA_IO_HUP);
A boolean describing whether the file descriptor should be closed automatically at the end of not;
A void pointer given to the callback; this is often called user data which means we can avoid static global variables.
Note: this event loop implementation is not reserved to PipeWire-related processing; it can be used as a main event loop in your processes.
That leads us to the other synchronisation and communication primitives used, which are all file-descriptor-based for integration with the event loop.
File-descriptor-based IPC
eventfd(2) is used as the main wake-up method when that is required, such as with node objects that must run their process method. signalfd(2) is used to register signal callbacks in the event-loop.
epoll(7), eventfd(2) and signalfd(2) being Linux-specific, it should be noted that there is an abstraction layer that allows one to use other primitives for implementations. Currently, Xenomai primitives are supported through this layer.
The main communication protocol is based upon a local streaming socket(2): socket(PF_LOCAL, SOCK_STREAM | SOCK_CLOEXEC | SOCK_NONBLOCK, 0). The encoding scheme used is called Plain Object Data (POD) and is a rather simple format; a POD has a 32-bits size, a 32-bits type followed by the content. There are basic types (none, bool, int, string, bytes, etc.) and container types (array, struct, object and sequence). In top of this encoding scheme is provided the Simple Plugin API (SPA) which implements a sort of Remote Procedure Call (RPC). See this PipeWire under the hood blog article that has a detailed section on POD, SPA and example usage of the provided APIs.
D-Bus
PipeWire and WirePlumber also optionally depend on the higher-level D-Bus communication protocol for specific features:
Flatpaks are desktop sandboxed applications, that rely on portal (a process that exposes D-Bus interfaces) to access system-wide features such as printing and audio. In our case, libpipewire-module-portal allows the portal process to handle permission management relative to audio for Flatpak applications. See module-portal.c and xdg-desktop-portal for more information.
WirePlumber, through its module-reserve-device, supports the org.freedesktop.ReserveDevice1 D-Bus interface. It allows one to reserve an audio device for exclusive use. See the quick and to-the-point specification about the interface for more information.
D-Bus support is required if Bluetooth is wanted, to allow communication with the BlueZ process. See the SPA bluez5 plugin.
Conclusion
Now that the overall concepts as well as design and implementation choices have been covered, it is time for some hands-on! We will carry on with a bare install based upon a Linux kernel and a Buildroot-built root filesystem image. Our goal will be to output sound to an USB ALSA PCM sink, from an audio file.
Do not hesitate to come back to this article later on, that might help you clear-up some blurry concepts if needed!
As explained in the first two blog posts, the BeagleBone boards are supported by a wide number of extension boards, called capes.
When such a cape is plugged in, the description of the devices connected to the board should be updated accordingly. As the available hardware is described by a Device Tree, the added devices on the cape should be described using a Device Tree Overlay, as described in the first blog post.
As explained in this post too, the bootloader is today’s standard place for loading Device Tree Overlays on top of the board’s Device Tree. Once you know which capes are plugged in, you can load them in U-Boot and boot Linux as in the following example:
This mechanism works fine, but every time you plug in a different cape, you have to tweak this sequence of commands to load the right overlay (the .dtbo file). This would be great if each cape could be detected automatically and so could be the corresponding overlays.
Actually, all this is possible and already supported in mainline U-Boot starting from version 2021.07. That’s what this article is about.
BeagleBone Black with multiple capes – We want to detect them automatically!
To identify which capes are plugged in, all you have to do is read the connected EEPROMs. You can test by yourself by booting a BeagleBone with a Debian image, and dumping the EEPROM contents as in the following example:
Of course, the above kind of command only works if the corresponding Device Tree Overlays are loaded. Otherwise, the Linux kernel won’t know that the I2C EEPROMs are available.
The U-Boot extension manager
In the latest Debian images proposed by BeagleBoard.org at the time of this writing, there is already a mechanism to detect the plugged capes based on the information on their I2C EEPROM. However, that was a custom mechanism, and BeagleBoard.org contracted Bootlin to implement a more generic mechanism in the official version of U-Boot.
This generic mechanism was implemented by my colleague Köry Maincent and added to U-Boot (since version 2021.07) by this commit.
Let’s test this mechanism by building and booting our own image. The following instructions apply to the BeagleBone Black board.
SD card preparation
Using cfdisk or a similar tool, prepare a micro-SD card with at least one partition which you mark as “Bootable”. Then format it with the FAT32 filesystem:
sudo mkfs.vfat -F 32 -n boot /dev/mmcblk0p1
Now, remove and plug the micro-SD card back in again. It should automatically be mounted on /media/$USER/boot.
Compiling U-Boot
We first need to install a cross-compiling toolchain if you don’t have one yet. Here’s how to do this on Ubuntu:
Then, let’s get the kernel sources and configure them:
git clone https://github.com/beagleboard/linux.git
cd linux
git checkout 5.10.100-ti-r40
export CROSS_COMPILE=arm-linux-gnueabihf-
export ARCH=arm
make omap2plus_defconfig
make menuconfig
In the configuration interface, enable compiling the Device Tree Overlays with CONFIG_OF_OVERLAY=y. Also set CONFIG_INITRAMFS_SOURCE="../rootfs.cpio". You can now compile the kernel and the Device Trees, and deploy them to the micro-SD card:
Configuring U-Boot and using the “extension” command
Now insert the micro-SD card in the BeagleBone Black. Connect the capes that you own. Then power on the board while holding the USR button (close to the USB host port).
On the serial line, you should see U-Boot 2022.04 starting. Interrupt the countdown by pressing any key, to access the U-Boot prompt:
U-Boot SPL 2022.04 (Apr 06 2022 - 15:04:53 +0200)
Trying to boot from MMC1
U-Boot 2022.04 (Apr 06 2022 - 15:04:53 +0200)
CPU : AM335X-GP rev 2.1
Model: TI AM335x BeagleBone Black
DRAM: 512 MiB
Core: 150 devices, 14 uclasses, devicetree: separate
WDT: Started wdt@44e35000 with servicing (60s timeout)
NAND: 0 MiB
MMC: OMAP SD/MMC: 0, OMAP SD/MMC: 1
Loading Environment from FAT... Unable to read "uboot.env" from mmc0:1...
not set. Validating first E-fuse MAC
Net: eth2: ethernet@4a100000, eth3: usb_ether
Hit any key to stop autoboot: 0
=>
Let’s try the extension manager now. First, we load the kernel image and Device Tree Binary (DTB) for the board:
=> fatload mmc 0:1 0x81000000 zImage
6219488 bytes read in 408 ms (14.5 MiB/s)
=> fatload mmc 0:1 0x82000000 am335x-boneblack.dtb
64939 bytes read in 10 ms (6.2 MiB/s)
Then, we set the RAM address where each Device Tree Overlay will be loaded:
Taking the relay cape as an example, you can see that the name of the Device Tree overlay was derived from the description in its EEPROM, which we dumped earlier.
Now, everything’s ready to load the overlay for the first cape (number 0):
=> extension apply 0
loading BBORG_RELAY-00A2.dtbo
1716 bytes read in 5 ms (335 KiB/s)
Or for all capes:
=> extension apply all
loading BBORG_RELAY-00A2.dtbo
1716 bytes read in 5 ms (335 KiB/s)
loading BB-CAPE-DISP-CT4-00A0.dtbo
5372 bytes read in 5 ms (1 MiB/s)
loading BBORG_COMMS-00A2.dtbo
1492 bytes read in 4 ms (364.3 KiB/s)
We are now ready to set a generic command that will automatically load all the overlays for the supported capes, whatever they are, and then boot the Linux kernel:
6228224 bytes read in 526 ms (11.3 MiB/s)
93357 bytes read in 10 ms (8.9 MiB/s)
BeagleBone Cape: Relay Cape (0x54)
BeagleBone Cape: BB-CAPE-DISP-CT43 (0x55)
BeagleBone Cape: Industrial Comms Cape (0x56)
Found 3 extension board(s).
loading BBORG_RELAY-00A2.dtbo
1716 bytes read in 5 ms (335 KiB/s)
loading BB-CAPE-DISP-CT4-00A0.dtbo
5372 bytes read in 5 ms (1 MiB/s)
loading BBORG_COMMS-00A2.dtbo
1492 bytes read in 4 ms (364.3 KiB/s)
Kernel image @ 0x81000000 [ 0x000000 - 0x5f0900 ]
## Flattened Device Tree blob at 82000000
Booting using the fdt blob at 0x82000000
Loading Device Tree to 8ffe4000, end 8fffffff ... OK
Starting kernel ...
[ 0.000000] Booting Linux on physical CPU 0x0
[ 0.000000] Linux version 5.10.100 (mike@mike-laptop) (arm-linux-gnueabihf-gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0, GNU ld (GNU Binutils for Ubuntu) 2.34) #8 SMP Wed Apr 6 16:25:24 CEST 2022
...
To double check that the overlays were taken into account, you can log in a the root user (no password) and type this command:
# ls /proc/device-tree/chosen/overlays/
BB-CAPE-DISP-CT4-00A0.kernel BBORG_RELAY-00A2.kernel
BBORG_COMMS-00A2.kernel name
Note: all the files used here, including the resulting U-Boot environment file, are available in this archive. All you have to do is extract the archive in a FAT partition with the bootable flag, and then you’ll be ready to boot your board with it, without any manipulation to perform in U-Boot.
How to add support for a new board
To prove that the new extension board manager in U-Boot was generic, Köry Maincent used it to support three different types of boards:
BeagleBone boards based on the AM3358 SoC from TI
The BeagleBone AI board, based on the AM5729 SoC from TI
The CHIP computer, based on the Allwinner R8 CPU, and its DIP extension boards.
To support a new board and its extension boards, the main thing to implement is the extension_board_scan() function for your board.
A good example to check is this commit from Köry which introduced cape detection capabilities for the TI CPUs and this second commit that enabled the mechanism on AM57xx (BeagleBone AI). A good ideas is also to check the latest version of board/ti/common/cape_detect.c in U-Boot’s sources.
Summary
The U-Boot Extension Board Manager is a feature in U-Boot which allows to automatically detect extension boards, provided the hardware makes such a detection possible, and automatically load and apply the corresponding Device Tree overlays. It was contributed by Köry Maincent from Bootlin, thanks to funding from BeagleBoard.org.
At the time of this writing, this functionality is supported on the BeagleBone boards (AM335x and AM57xx), on the CHIP computer (Allwinner R8), and since more recently, on Compulab’s IOT-GATE-iMX8 gateways.
With the combination of this blog post and the former two (see the links at the beginning), it should be clear how a specification can be written to use a combination of Device Tree symbols, Udev rules and extension board identifiers to make expansion header hardware “just work” when plugged in to various boards with compatible headers. BeagleBoard.org would be proud if our example inspired other community board maintainers.
Bootlin would like to thank BeagleBoard.org for funding the development and deployment of this infrastructure in mainline U-Boot, and the creation of these three blog posts on Device Tree overlays.
Linux 5.18 has been released a bit over a week ago. As usual, we recommend the resources provided by LWN.net (part 1 and part 2) and KernelNewbies.org to get an overall view of the major features and improvements of this Linux kernel release.
Bootlin engineers have collectively contributed 80 patches to this Linux kernel release, making us the 28th contributing company according to these statistics.
Alexandre Belloni, as the RTC subsystem maintainer, continued to improve the overall subsystem, and migrate drivers to new features and mechanisms introduced in the core RTC subsystem
Clément Léger contributed a new RTC driver that allows to use the RTC exposed by the OP-TEE Trusted Execution Environment, as well as a few other fixes
Hervé Codina and Luca Ceresoli contributed some fixes: Hervé to the dw-edma dmaengine driver, and Luca to the Rockchip RK3308 pinctrl driver
Miquèl Raynal, as the MTD subsystem co-maintainer, contributed the remainder of his work to generalize the support of ECC handling, and allow both parallel and SPI NAND to use either software ECC, on-die ECC, or ECC done by a dedicated controller. Included in this work is a new driver for the Macronix external ECC engine, in drivers/mtd/nand/ecc-mxic.c
Miquèl Raynal also made a few contributions to the 802.15.4 part of the networking stack, and we have more contributions in this area coming up.
Paul Kocialkowski contributed a small fix to Allwinner Device Tree files, and another attempt at fixing an issue with the display panel detection/probing in the DRM subsystem
Tomorrow, on May 18, the third edition of Live Embedded Event will take place. Live Embedded Event is a free and fully online conference, dedicated to embedded topics at large. One can register directly online to receive a link to attend the conference.
Bootlin will be participating to this third edition, with 3 talks from 3 different Bootlin engineers:
Michael Opdenacker on LLVM tools for the Linux kernel, at 12:00 UTC+2 in Track 3. Details: Recent versions of Linux can be compiled with LLVM’s Clang C language compiler, in addition to Gcc, at least on today’s most popular CPU architectures. This presentation will show you how. Cross-compiling works differently with Clang: no architecture-specific cross-compiling toolchain is required. We will compare the Clang and Gcc compiled kernels, in terms of size and boot time. More generally, we will discuss the concrete benefits brought by being able to compile the kernel with this alternative compiler, in particular the LLVM specific kernel Makefile targets: clang-tidy and clang-analyzer.
Grégory Clement on AMP on Cortex A9 with Linux and OpenAMP, at 15:30 UTC+2 in Track 2. Details: While, usually, the Cortex A9 cores are used in SMP, one could want use one of the core to run an other OS. In this case the system becomes AMP. Typically, it allows running a dedicated real time OS on a core. This presentation will show the step that allow having this support using open sources stacks. First we will see what OpenAMP is, then how the Linux kernel can communicate with external OS using remote proc message, and finally what to adapt in the Linux kernel and OpenAMP in order to support the usage of a Cortex A9. This was experimented on an i.MX6 but the solution presented has the advantage to be easily adapted on any SoC using Cortex A9.
Thomas Perrot on PKCS#11 with OP-TEE at 15:00 UTC+2 in Track 2. Details:
PKCS#11 is a standard API that allows to manage cryptographic tokens, regardless of the platform such as Hardware Security Modules, Trusted Plaform Modules or smart cards. Moreover, modern processors offer a secure area, named Trusted Execution Environment (TEE) that allows the isolation of some operations, datas and devices to guarantee their integrity and confidentiality. OP-TEE is an open source implementation of Trusted Execution Environment that runs in parallel with the operating system, as a companion. In this talk, we will first introduce PKCS#11, then OP-TEE, and finally look at how PKCS#11 operations can be performed through OP-TEE, and what are the benefits. Our presentation will be illustrated with examples based on the NXP i.MX8QXP platform, but should be applicable to other platforms that have OP-TEE support.
Join us at Live Embedded Event, and discover our talks as well as the many other talks from other speakers!
In addition, both Thomas and Alexandre will be speaking at the event:
Thomas Petazzoni will give a talk Buildroot: what’s new?, providing an update on the improvements and new features in the Buildroot build system that have been integrated over the past two years
Alexandre Belloni will give a talk Yocto Project Autobuilders and the SWAT Team, during which he will explain what’s happening behind in the scenes in the Yocto Project to review and validate contributions before they are integrated.
Thomas and Alexandre will also naturally be available during the event to discuss business or career opportunities, so do not hesitate to get in touch if you’re interested.
Finally, prior to the event, Thomas Petazzoni will be in the Bay Area on June 13-15, also available for meetings or discussions.
As we mentioned in our last blog post about OP-TEE 3.16, Bootlin planned to and contributed some interesting features in the recently released OP-TEE 3.17 ! Here is a short presentation of our contributions to this release:
Summary
During this release cycle, Bootlin contributed the following features:
Watchdog support
Generic watchdog API
OP-TEE Watchdog service compatible with arm,smc-wdt Linux driver
As part of our work on Microchip SAMA5D2 support in OP-TEE, we wanted to have support for the SAMA5D2 watchdog. Doing so without exposing the watchdog to Linux would have been useless and thus, we implemented and contributed a new generic watchdog API to OP-TEE. This interface allows registering a watchdog against the system and exposing it to Linux through a specific SMC handler that interfaces with the Linux arm,smc-wdt compatible driver (see drivers/watchdog/arm_smc_wdt.c in the Linux kernel code). Our generic watchdog API is obviously used by the new watchdog driver for Microchip SAMA5D2, but was also quickly leveraged by ST who contributed a new watchdog driver for stm32mp1 based on this new watchdog API.
RTC
On Microchip SAMA5D2, the RTC is part of the system controller which needs to be secured since it contains critical features. Once in the secure world, the RTC is not available to the normal world. In order to expose this RTC device to the normal world (and particularly for Linux RTC subsystem), a new Pseudo Trusted Application (PTA) was added. This PTA communicates with a Linux OP-TEE compatible RTC driver and allows to get/set the date and time. This driver is generic and will allow any vendor which adds RTC support to OP-TEE to expose it transparently to Linux.
Contribution details
A total of 29 commits were contributed for OP-TEE 3.17:
Do not hesitate to contact us if you need help and support to integrate or deploy OP-TEE on your platform, either Microchip platforms, but also other ARM32 or ARM64 platforms.
Most of the BeagleBone boards from BeagleBoard.org share the same form factor, have the same headers and therefore can accept the same extension boards, also known as capes in the BeagleBoard world.
Of course, a careful PCB design was necessary to make this possible.
This must have been relatively easy with the early models (BeagleBone Black, Black Wireless, Green, Green Wireless, Black Industrial and Enhanced) which are based on the same Sitara AM3358 System on Chip (SoC) from Texas Instruments. However, the more recent creation of the BeagleBone AI board and keeping compatibility with existing capes must have been a little more complicated, as this board is based on a completely different SoC from Texas Instruments, the Sitara AM5729.
BeagleBone AI BeagleBone Green BeagleBone Black
Once the PCB design challenge was completed, the BeagleBoard.org crew set itself another challenge: implement software that supports each BeagleBone cape in the same way, whatever the board, in particular:
To have unique identifiers for devices in Linux, so that there is a stable name for Linux devices, even if at the hardware level they are connected differently, depending on whether the base board has a Sitara AM3358 and Sitara AM5729 SoC.
To have DT overlays for capes that are applicable to all base boards, even if peripherals are connected to different buses of the SoCs.
This article will explore the software solutions implemented by BeagleBoard.org. Their ideas can of course be reused by other projects with similar needs.
The need for a cape standard
A good summary can be found on Deepak Khatri’s Google Summer of Code 2020 page:
The idea of this project was to make the same user space examples work with both BeagleBone Black and BeagleBone AI, using the same references to drivers for peripherals assigned to the same pins between BeagleBone Black and BeagleBone AI. Also, Same DT overlays should work (whenever possible) for both BBB and BBAI, with updated U-Boot cape manager DT overlays will be automatically loaded during boot.
Software setup
The below instructions are for people owning the BeagleBone AI board and any other BeagleBone board, and interested in exploring the devices on their boards by themselves.
Uncompress each image, insert a micro-SD card in the card read in your PC, and then flash the corresponding card. Here are example commands, assuming that the micro-SD card is represented by the /dev/mmcblk0 device:
Connect the serial line of each board to your computer and then boot each board with it:
For BeagleBone AI: its sufficient to have the micro-SD card inserted.
On other BeagleBone boards, you may need to hold a button when you power up the board, to make it boot from the micro-SD card instead of from the internal eMMC. On the BeagleBone Black boards, for examples, that’s the USER button next to the USB host port. Note that you won’t need to do this again when you reset the board. The board will continue to boot from the external micro-SD card until it’s powered off.
You can connect with the default user, or connect as user root with password root.
Then, connect each board to the Internet, and get the latest package updates:
sudo apt update
sudo apt dist-upgrade
It’s then time to upgrade the kernel to the latest version supported by BeagleBoard. To do so, you’ll have to manually update the /opt/scripts/tools/update_kernel.sh file. In this file, go to the # parse commandline options section and add the below lines:
--lts-5_10-kernel|--lts-5_10)
kernel="LTS510"
;;
You can can then upgrade to the latest 5.10 kernel:
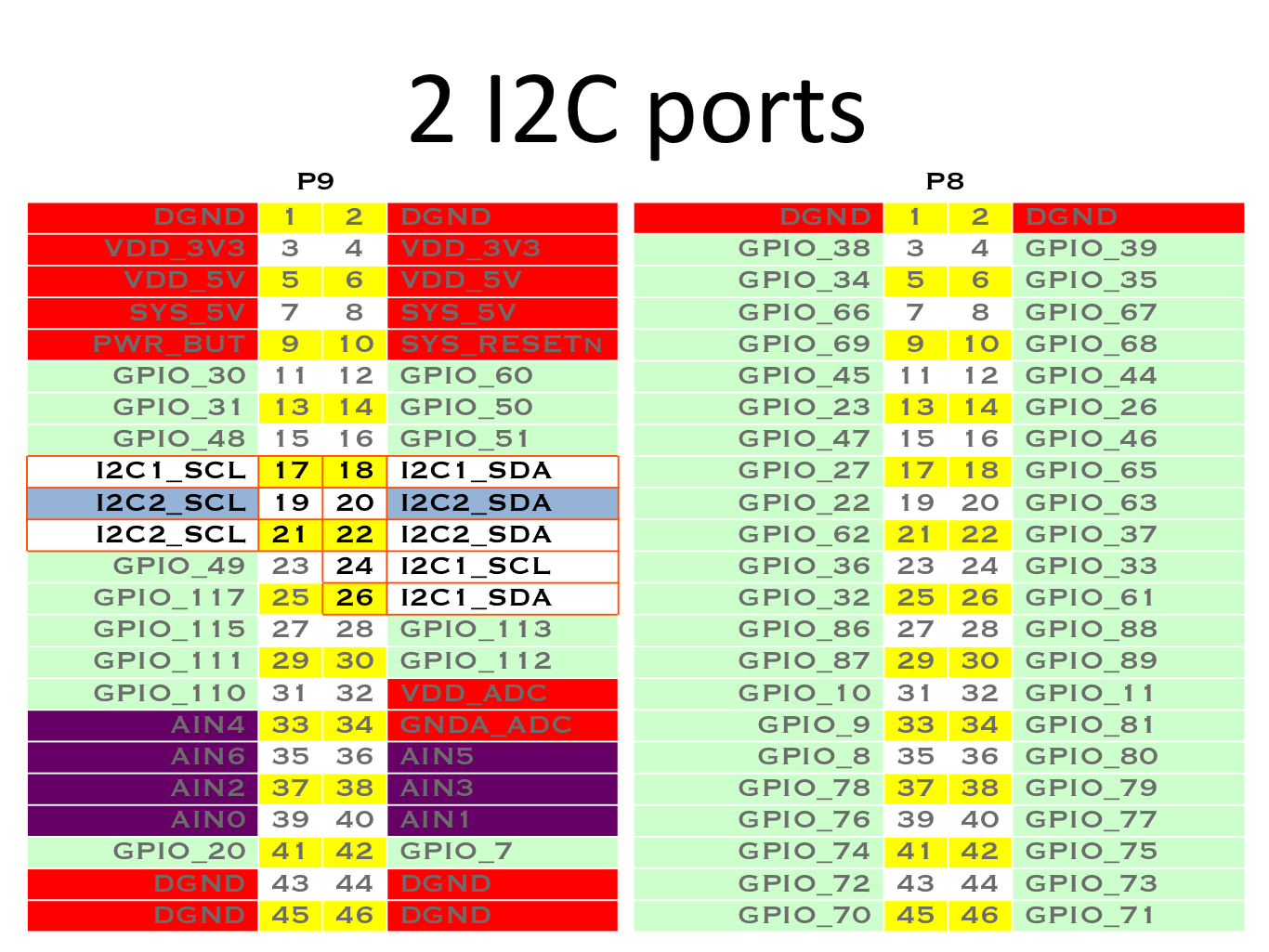
Note that on the BeagleBone Black, I2C1 and I2C2 are available at two different locations.
So, for both types of boards, we have at least I2C buses on P9_17/18, P9_19/20 and P9_24/26. However, that’s complicated because these pins don’t correspond to the same I2C buses. Therefore, users have to know that P9_19/20 correspond to I2C2 on BeagleBone Black and to I2C4 on BeagleBone AI.
The devices in /dev/ reflect such differences.
Here’s what we have on the BeagleBone AI:
root@beaglebone:~# ls -la /dev/i2c-*
crw------- 1 root root 89, 0 Mar 23 15:00 /dev/i2c-0
crw------- 1 root root 89, 3 Mar 23 15:00 /dev/i2c-3
Note that here with the AM5729 SoC, the first I2C bus is I2C1. Hence, /dev/i2c-0 corresponds to I2C1 (which is another I2C bus available on the SoC but not available through the cape headers) and /dev/i2c-3 corresponds to I2C4. Also note that I2C5 is not exposed in the default configuration that we have here, most probably because the corresponding header pins are used for other purposes.
And now let’s look at what we have on the BeagleBone Black:
root@beaglebone:~# ls -la /dev/i2c-*
crw------- 1 root root 89, 0 Mar 23 16:16 /dev/i2c-0
crw------- 1 root root 89, 1 Mar 23 16:17 /dev/i2c-1
crw------- 1 root root 89, 2 Mar 23 16:17 /dev/i2c-2
Here with the AM3358 SoC, /dev/i2c-0 corresponds to I2C0, /dev/ic2-1 to I2C1 and /dev/ic2-2 to I2C2.
So, on a running system, how to know which I2C bus device corresponds to the P9_19/20 header pins?
You can see that both devices, though they correspond to different devices, share the same symlink property, which is used to create a symbolic link in /dev/bone/i2c/ to the actual bus device file.
Let’s see such symbolic links on the BeagleBone AI:
root@beaglebone:~# ls -la /dev/bone/i2c/
total 0
drwxr-xr-x 2 root root 80 Jan 1 2000 .
drwxr-xr-x 4 root root 80 Jan 1 2000 ..
lrwxrwxrwx 1 root root 11 Mar 23 15:00 0 -> ../../i2c-0
lrwxrwxrwx 1 root root 11 Mar 23 15:00 2 -> ../../i2c-3
And on the BeagleBone Black:
root@beaglebone:~# ls -la /dev/bone/i2c/
total 0
drwxr-xr-x 2 root root 100 Mar 23 16:16 .
drwxr-xr-x 5 root root 100 Mar 23 16:16 ..
lrwxrwxrwx 1 root root 11 Mar 23 16:16 0 -> ../../i2c-0
lrwxrwxrwx 1 root root 11 Mar 23 16:17 1 -> ../../i2c-1
lrwxrwxrwx 1 root root 11 Mar 23 16:17 2 -> ../../i2c-2
You can see that at least /dev/bone/i2c/0 and /dev/bone/i2c/2 are shared between both types of boards. Userspace code examples can then support different boards by referring to such device file links, for example by using the I2C tools commands.
The symbolic links are created from the Device Tree sources not by the Linux kernel, but by the udev device manager, thanks to the following rule found in /etc/udev/rules.d/10-of-symlink.rules in the BeagleBoard Debian distribution:
# allow declaring a symlink for a device in DT
ATTR{device/of_node/symlink}!="", \
ENV{OF_SYMLINK}="%s{device/of_node/symlink}"
ENV{OF_SYMLINK}!="", ENV{DEVNAME}!="", \
SYMLINK+="%E{OF_SYMLINK}", \
TAG+="systemd", ENV{SYSTEMD_ALIAS}+="/dev/%E{OF_SYMLINK}"
Accessing other devices
Other devices are available in the same way through symbolic links in /dev/bone/, for example UART (serial port) devices.
Let’s check on the BeagleBone AI (run sudo apt install tree first):
Another challenge is with userspace software examples directly refer to header pins by their names. Here is a BoneScript push button demo, for example:
var b = require('bonescript');
b.pinMode('P8_19', b.INPUT);
b.pinMode('P8_13', b.OUTPUT);
setInterval(check,100);
function check(){
b.digitalRead('P8_19', checkButton);
}
function checkButton(x) {
if(x.value == 1){
b.digitalWrite('P8_13', b.HIGH);
}
else{
b.digitalWrite('P8_13', b.LOW);
}
}
For AM3358 BeagleBone boards, the am335x-bone-common-univ.dtsi file already associates the P8_19 name to a specific GPIO:
However, this driver is specific to the BeagleBoard.org kernel, and the Device Tree for Beagle Bone AI doesn’t use it yet, so this aspect is still work in progress. The main goal remains though: define generic names for header pins, which map to specific GPIOs on different boards.
The goal as stated in the beginning is to use the same Device Tree overlays on both types of SoCs. While as of today it doesn’t seem possible to generate compiled Device Tree Overlays (DTBO) which would support both SoCs at the same time, the BeagleBoard.org engineers have come up with a solution to achieve this at source level. This means that, for each cape to support, the Device Tree Overlay binaries for the supported SoCs can be produced from a unique source file.
While this hasn’t been deployed yet in the 5.10 BeagleBoard kernel, such source code is already available in Deepak Khatri’s own tree.
/*
* Copyright (C) 2020 Deepak Khatri
*
* Virtual cape for /dev/bone/can/1
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation.
*/
/dts-v1/;
/plugin/;
/*
* Helper to show loaded overlays under: /proc/device-tree/chosen/overlays/
*/
&{/chosen} {
overlays {
BONE-CAN1 = __TIMESTAMP__;
};
};
/*
* Update the default pinmux of the pins.
* See these files for the phandles (&P9_* & &P8_*)
* https://github.com/lorforlinux/BeagleBoard-DeviceTrees/blob/compatibility/src/arm/am335x-bone-common-univ.dtsi
* https://github.com/lorforlinux/BeagleBoard-DeviceTrees/blob/compatibility/src/arm/am572x-bone-common-univ.dtsi
*/
&ocp {
P9_24_pinmux { pinctrl-0 = <&P9_24_can_pin>;}; /* can rx */
P9_26_pinmux { pinctrl-0 = <&P9_26_can_pin>;}; /* can tx */
};
/*
* See these files for the phandles (&bone_*) and other bone bus nodes
* https://github.com/lorforlinux/BeagleBoard-DeviceTrees/blob/compatibility/src/arm/bbai-bone-buses.dtsi
* https://github.com/lorforlinux/BeagleBoard-DeviceTrees/blob/compatibility/src/arm/bbb-bone-buses.dtsi
*/
&bone_can_1 {
status = "okay";
};
The &ocp code applies the pin muxing definitions for CAN on P9_24 (&P9_24_can_pin) and P9_26 (&P9_26_can_pin), which of course are different on AM3358 and AM5729.
By adding a symlink property to the Device Tree sources, BeagleBoard.org has made it possible to make userspace code, in particular its code examples, support all the BeagleBone boards at the same time, even though the devices they drive have are numbered differently on different SoCs.
Such a technique may be reused by other projects interested in running the same software on boards based on different SoCs.
As far as GPIOs are concerned, the drivers/gpio/gpio-of-helper.c driver is specific to the BeagleBoard.org kernel and is unlikely to be accepted in the mainline kernel in its current state. However, there are other solutions, supported by the mainline kernel, to associate names to GPIOs and then to look up such GPIOs by name through libgpiod.
Last but not least, it’s possible to use the same Device Tree Overlay source code to support an extension board on similar boards, just by using common definitions having different values on each different platform. Any project can reuse this idea, which just uses standard Device Tree syntax.
Bootlin thanks BeagleBoard.org for funding the creation of this blog post. Note that another post is coming in the next weeks, about the extension board manager we added to U-Boot thanks to funding from BeagleBoard.org.
Linux 5.17 has been released last Sunday. As usual, the best coverage of what is part of this release comes from LWN (part 1 and part 2), as well as KernelNewbies (unresponsive at the time of this writing) or CNX Software (for an ARM/RISC-V/MIPS focused description).
Bootlin contributed just 34 patches to this release, which isn’t a lot by the number of patches, but in fact includes a number of important new features. Also, we have many more contributions being discussed on the mailing lists or in preparation. For this 5.17 release here are the highlights of our contributions:
Alexandre Belloni, as the maintainer of the RTC subsystem, contributed one improvement to an RTC driver
Clément Léger improved the Microchip Ocelot Ethernet switch driver performance by implementing FDMA support. This allows network packets that are going from the switch to the CPU, or from the CPU to the switch to be received/sent in a much more efficient fashion than before. The Microchip Ocelot Ethernet switch driver was developed and upstreamed several years ago by Bootlin, see our previous blog post.
Clément Léger also contributed smaller fixes: a bug fix in the core software node code, and one PHY driver fix.
Hervé Codina implemented support for GPIO interrupts on the old ST Spear320 platform.
Miquèl Raynal contributed a brand new NAND controller driver, for the NAND controller found in the Renesas RZ/N1 SoC. We expect to contribute to many more aspects of the Renesas RZ/N1 Linux kernel support in the next few months.
Miquèl Raynal contributed a few Device Tree changes enabling the ADC on the Texas Instruments AM473x platform, after contributing the driver changes a few releases ago.
Miquèl Raynal started contributing some improvements to the 802.15.4 Linux kernel stack, and we also have many more changes in the pipe for this Linux kernel subsystem.
Thomas Perrot added support for the Sierra EM919X modem to the existing MHI PCI driver.
In the past months, the Linux kernel driver for the Ethernet MAC found in a number of Marvell SoCs, mvneta, has seen quite a few improvements. Lorenzo Bianconi brought support for XDP operations on non-linear buffers, a follow-up work on the already-great XDP support that offers very nice performances on that controller. Russell King contributed an improved, more generic and easier to maintain phylink support, to deal with the variety of embedded use-cases.
At that point, it’s getting difficult to squeeze more performances out of this controller. However, we still have some tricks we can use to improve some use-cases so in the past months, we’ve worked on implementing QoS features on mvneta, through the use of mqprio.
Multi-queue support
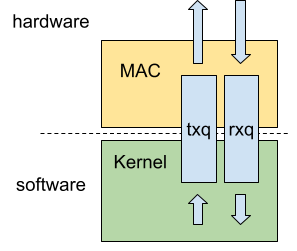
A simple Ethernet NIC (Network Interface Controller) could be described as a controller that handles some protocol-level aspect of the Ethernet standard, where the incoming and outgoing packets would be enqueued in a dedicated ring-buffer that serves as an interface between the controller and the kernel.
The buffer containing packets that needs to be sent is called the Transmit Queue, often written as txq. It’s fed by the kernel, where the NIC driver converts some struct sk_buff objects called skb, that represent packets trough their journey in the kernel, into buffers that are enqueued in the txq.
On the ingress side, the Receive Queue, written rxq, is fed by the MAC, and dequeued by the NIC driver, who creates skb containing the payload and attached metadata.
In the end, every incoming or outgoing packet is enqueued and dequeued in a typical first-in first-out fashion. When the queue is full, packets are dropped, everything is neat, simple and deterministic.
However, typical use-cases are never simple. Most modern NICs have several queues in TX and RX. On the receive side, it’s useful to have multiple queues for performance reasons. When receiving packets, we can spread the traffic across multiple queues (with RSS for example), and have one CPU core dedicated to each queue. More complex use-cases can be expressed, such as flow steering, that you can learn about in the kernel documentation.
On the transmit side, it’s a bit less obvious why we want to have multiple queues. If the CPU is the bottleneck in terms of performances, having multiple TX queues won’t help much. Still, there are ways to benefit from having multiple TX queues on a multi-cpu system with XPS.
However, when the line-rate is the bottleneck, having multiple queues gets useful. By sorting the outgoing traffic by priority and assign each priority to a TX queue, the NIC can then pick the next packet to send from the highest priority queue until it’s empty, and then move on to the next priority. That way, we implement what’s called QoS (Quality of Service), where we care about high-priority traffic making it through the controller.
QoS itself is useful for various reasons. Besides the obvious prioritization of high-value streams for not-so-neutral networking, we can also imagine tagging management traffic as high-priority, to guarantee the ability to remotely access a machine under heavy traffic.
Other applications can be in the realm of Time Sensitive Networking, where it’s important that time-sensitive traffic gets sent right-away, using the high-priority queues as shortcuts to bypass the low-priority over-crowded queues.
NICs can use more advanced algorithms to pick the queue to de-queue the packet from, in a process called arbitration, to give low-priority traffic a chance to get sent even when high-priority traffic takes most of the bandwidth.
Typical algorithms range from strict priority-based FIFO to more flexible Weighted Round-Robin arbitration, to allow at least a few low-priority packets to leave the NIC.
In the case of mvneta, we’re limited in terms of what we can do in the receive path. Most of the work we’ve done focused on the transmit side.
Traffic Priorisation and Arbitration
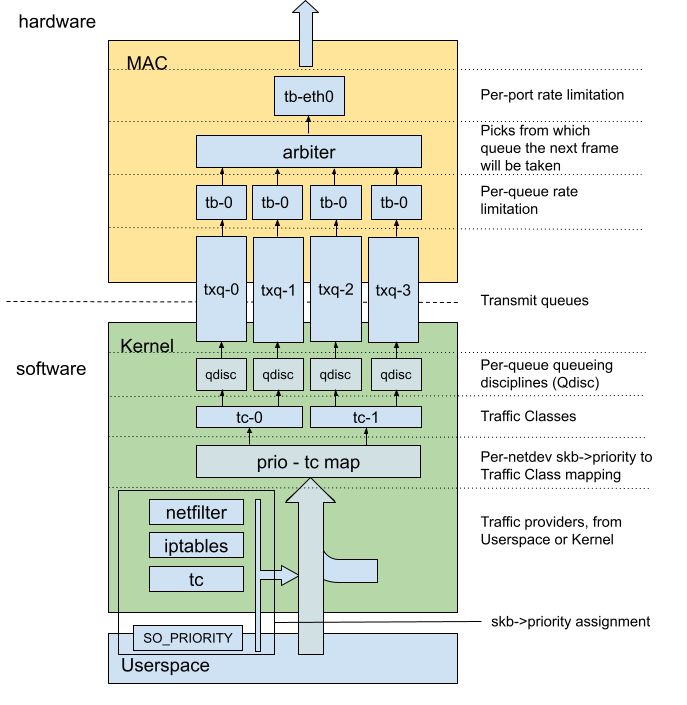
Multi-queue support on the TX path is a three-fold process.
First, we have to know which packets are high-priority and which aren’t, by assigning a value to the skb->priority field.
There are several ways of doing so, using iptables, nftables, tc, socket parameters through SO_PRIORITY, or switching parameters. This is outside of the scope of this article, we’ll assume that incoming packets are already prioritized through one of the above mechanisms.
Once the packet comes into the network stack as a skb, we need to assign it to a TX queue. That’s where tc-mqprio comes in play.
In that second step, we build a mapping between priorities and queues. This mapping is done through the use of an intermediate mapping, the Traffic Classes. A Traffic Class is a mapping between N priorities and M transmit queues. We therefore have 2 levels of mappings to configure :
The priority to Traffic Class mapping (N to 1 mapping)
The Traffic Class to TX queue mapping (1 to M mapping)
All of this is done in one single tc command. We’re not going to dive too much into the tc tool itself, but we’ll still see a bit how tc-mqprio works.
Queuing Disciplines (QDiscs) are algorithms you use to select how and when you enqueue and dequeue traffic on a NIC. It benefits from great software support, but can also be offloaded to hardware, as we’ll see.
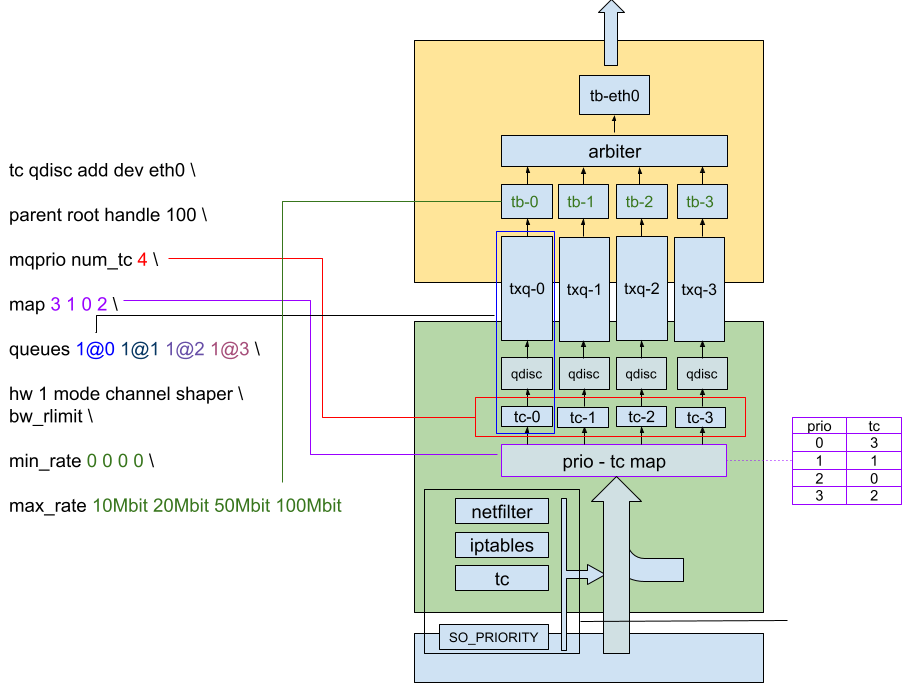
So the first part of the command is about attaching the mqprio QDisc to the network interface :
tc qdisc add dev eth0 parent root handle 100 mqprio
After that, we configure the traffic classes. Here, we create 8 traffic classes :
num_tc 8
And then we map each class to a priority. In this list, the n-th element corresponds to the class you want to assign to priority n. Here, we map the 8 first priorities to a dedicated class. Priorities that aren’t assigned a class are mapped to the class 0.
map 0 1 2 3 4 5 6 7
Finally, we map each class to a queue. Classes can only be assigned a contiguous set of queues, so the only parameters needed for the mapping are the number of queues assigned to the class (the number before the @), and the offset in the queue list (after the @). We specify one mapping per class, the m-th element in the list being the mapping for class number m. In the following example, we simply assign one queue per traffic class :
queues 1@0 1@1 1@2 1@3 1@4 1@5 1@6 1@7
Under the hood, tc-mqprio will actually assign one QDisc per queue and map the Traffic Classes to these QDiscs, so that we can still hook other tc configurations on a per-queue basis.
Finally, we enable hardware offloading of the prioritization :
hw 1
The last part of the work consists in configuring the hardware itself to correctly prioritize each queue. That’s done by the NIC driver, which gets the configuration from the tc hooks.
If we take a look at the Hardware, we see that the queues are exposed to the kernel, which will enqueue packets into them. Each queue then has a Bandwidth Limiter, followed by the arbitration layer. Finally, we have one last global Rate limiter, and the path then continues to the egress blocks of the controller.
The arbiter configuration is easy, it’s just a matter of enabling the strict priority arbitration in a few registers.
Let’s summarize what the stack looks like :
Traffic shaping
Being able to prioritize outgoing traffic is good, but we can step-it up by allowing to limit the rate on each queue. That way, we can neatly organize and control how we want to use our bandwidth, not on a per-packet level but really on a bits/s basis.
Controlling the rate of individual flows or queues is called Traffic Shaping. When configuring a shaper, not only do we focus on the desired max rate, but also how we deal with traffic bursts. We can smooth them by tightly controlling how and when we send packets, or we can allow some burstiness by being more lenient on how often we enforce the rate limitation.
In the mvneta hardware, we have 2 levels of shaping : one level of per-queue shapers, and one per-port shaper. They can all be controlled semi-independently, some parameters being shared between all shapers.
With mqprio, the shapers are configured on a per-Traffic-Class basis. Since the hardware only allows per-queue shaping, we enforce in the driver that one traffic class is assigned to only one queue.
A final configuration with mqprio looks like this :
Most shapers use a variant of the Token Bucket Filter algorithm. The principle is the following :
Each queue has a Token Bucket, with a limited capacity. When a packet needs to be sent, one token per bit in the packet gets taken from the bucket. If the bucket is empty, transmission stops. The bucket then gets refilled at a configurable rate, with a configurable amount of tokens.
Configuring the TBF for each queue boils down to setting a few parameters :
– The Bucket Size, sometimes called burst, buffer or maxburst.
It should be big enough to accommodate for the shaping rate required, but not too big. If the bucket is too big and you have a very slow traffic going out, the bucket is going to fill up to its full size. When you suddenly have a lot of traffic to send, you’ll first have a huge burst, the time for the bucket to empty, before the traffic starts to actually get limited. Unlike the tc-tbf interface, tc-mqprio doesn’t allow to change the burst size, so it’s up to the driver to set it.
– The Refill Rate, sometimes called tick, defining how often you refill the bucket.
– The Refill Value, defining how many tokens you put back into the bucket at each refill.
These two, combined together, define the actual rate limitation. The approach taken to select the value is to select a fixed value for one of the parameters, and vary the other one to select the desired rate. In the case of mvneta, we chose to use a fixed refill rate, and change the refill value. This means that we have a limited resolution in the rates we can express. In our case, we have a 10kbps resolution, allowing us to cover any rate limitation between 10kbps and 5Gbps, with 10k increments.
– One final parameter is the minburst or MTU parameter, and controls the minimum amount of tokens required to allow packet transmission.
Since transmission stops when the bucket is empty, we can end-up with an empty bucket in the middle of a packet being transmitted.The link-partner may not be too happy about that, so it’s common to set the Maximum Transmission Unit as the minimum amount of tokens required to trigger transmission.
That way, we are sure that when we start sending a packet, we’ll always have enough tokens in the bucket to send the full packet. We can play a bit with this parameter if we want to buffer small packets and send them in a short burst when we have enough. In our case, we simply configured it as the MTU, which is good enough for most cases.
In the end, the gains are not necessarily measurable in terms of raw performances, but thanks to mqprio and traffic shaping, we can now have better control on the traffic that comes out of our interface.
There are tons of other use-cases, for example limiting per-vlan speeds, or in contrary making sure that traffic on a specific vlan has the highest priority, and all of that mostly offloaded to the hardware itself !
 In this article, we show how to build a custom Linux distribution that includes a Flutter Embedder that uses the DRM/EGLStream backend, in order to run the Flutter Gallery application on the NVIDIA Tegra Xavier NX platform.
In this article, we show how to build a custom Linux distribution that includes a Flutter Embedder that uses the DRM/EGLStream backend, in order to run the Flutter Gallery application on the NVIDIA Tegra Xavier NX platform.



 Tomorrow, on May 18, the third edition of
Tomorrow, on May 18, the third edition of